前言
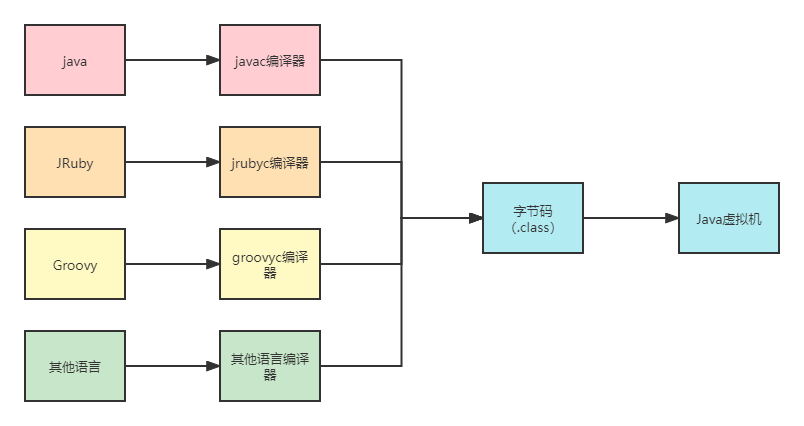
自上一篇Claas文件结构,我们了解Java代码编译成的字节码存储的具体细节。
本篇文章,我们需要理解虚拟机加载Class文件的过程。
环境:
操作系统:win10
JDK版本:1.8.0_291
本文所有内容都是基于以上环境的,如果有异议的地方欢迎邮件交流。
自上一篇Claas文件结构,我们了解Java代码编译成的字节码存储的具体细节。
本篇文章,我们需要理解虚拟机加载Class文件的过程。
环境:
操作系统:win10
JDK版本:1.8.0_291
本文所有内容都是基于以上环境的,如果有异议的地方欢迎邮件交流。
随着业务发展,系统的越来越复杂,几乎每个公司的系统都会从单体转向分布式,随之而来绕不开的问题就是分布式事务,下面来探讨几种主流的分布式事务解决方案
操作系统:macOS
Mysql:8
业务中需要对查询结果进行时间倒序排列,然后将几个查询子集合并,sql如下:
select distinct tmp.user_id as userId,
tmp.real_name as realName,
tmp.mobile as mobile,
tmp.register_time,
tmp.source
from ((select user_id, real_name, mobile, register_time, '直属粉丝' as source from user where superior_id = ?1)
union all
(select user_id, real_name, mobile, register_time, '间推粉丝' as source
from user
where superior_id in (select user_id from user where superior_id = ?1)) ) as tmp