随着业务发展,系统的越来越复杂,几乎每个公司的系统都会从单体转向分布式,随之而来绕不开的问题就是分布式事务,下面来探讨几种主流的分布式事务解决方案
分布式事务解决方案
由于分布式事务方案,无法做到完全的ACID的保证,没有一种完美的方案,能够解决掉所有业务问题。因此在实际应用中,会根据业务的不同特性,选择最适合的分布式事务方案。
两阶段提交(2PC)/XA
XA是由X/Open组织提出的分布式事务的规范,XA规范主要定义了(全局)事务管理器(TM)和(局部)资源管理器(RM)之间的接口。本地的数据库如mysql在XA中扮演的是RM角色
事务流程大致如下:
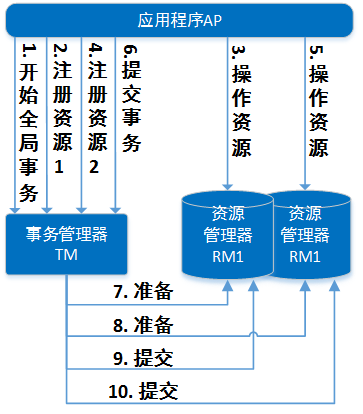
大致的流程:
第一阶段(prepare):事务管理器向所有本地资源管理器发起请求,询问是否是 ready 状态,所有参与者都将本事务能否成功的信息反馈发给协调者;
第二阶段 (commit/rollback):事务管理器根据所有本地资源管理器的反馈,通知所有本地资源管理器,步调一致地在所有分支上提交或者回滚。
特点:
- 简单易理解,开发容易
- 对资源长时间锁定,并发度低
TCC(Try-Confirm-Cancel)
关于 TCC(Try-Confirm-Cancel)的概念,最早是由 Pat Helland 于 2007 年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文提出。 TCC 事务机制相比于上面介绍的 XA,解决了其几个缺点:
- 解决了协调者单点,由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。
- 同步阻塞:引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。
- 数据一致性,有了补偿机制之后,由业务活动管理器控制一致性
TCC
Try 阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
Confirm 阶段:确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作满足幂等性。要求具备幂等设计,Confirm 失败后需要进行重试。
Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源 Cancel 操作满足幂等性 Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致。
在 Try 阶段,是对业务系统进行检查及资源预览,比如订单和存储操作,需要检查库存剩余数量是否够用,并进行预留,预留操作的话就是新建一个可用库存数量字段,Try 阶段操作是对这个可用库存数量进行操作。
基于 TCC 实现分布式事务,会将原来只需要一个接口就可以实现的逻辑拆分为 Try、Confirm、Cancel 三个接口,所以代码实现复杂度相对较高。
具体实现可以参考:tcc详解
TCC 需要事务接口提供 try, confirm, cancel 三个接口,提高了编程的复杂性。依赖于业务方来配合提供这样的接口,推行难度大,所以一般不推荐使用这种方式。
本地消息表
本地消息表这个方案最初是 ebay 架构师 Dan Pritchett 在 2008 年发表给 ACM 的文章完整方案。
该方案中会有消息生产者与消费者两个角色,假设系统 订单服务 是消息生产者,支付服务 是消息消费者,其大致流程如下:
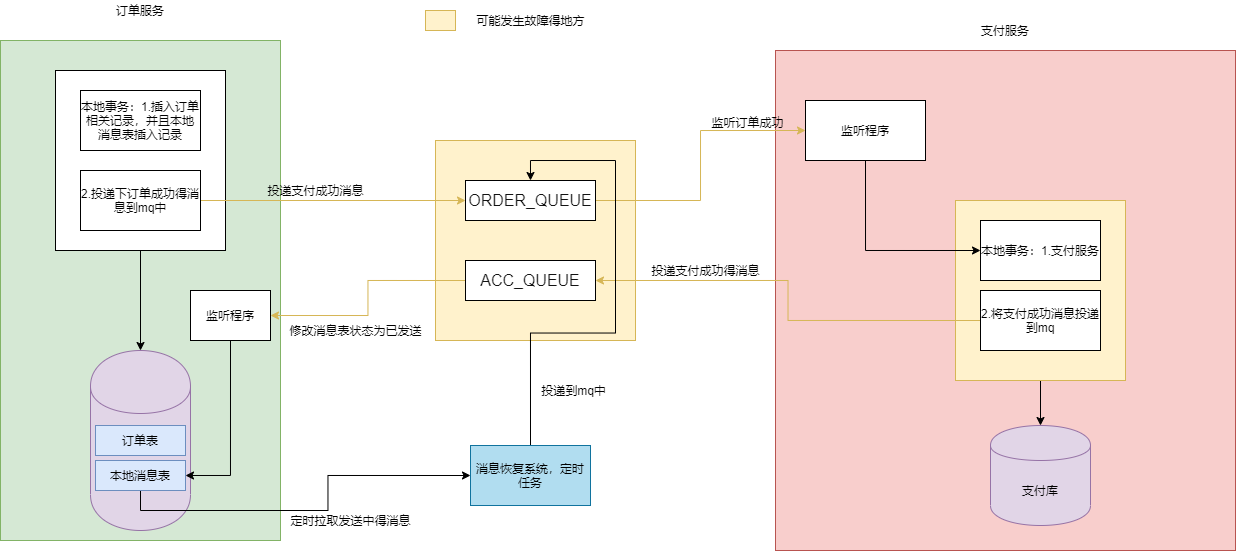
- 在订单库中引入一张消息表来记录订单消息,即用户下单成功后同时往这张消息表插入一条下单成功的消息,状态为“发送中”。注意订单逻辑和插入消息表的代码要包裹在一个事务里面,这里保证了本地事务的强一致性。即订单逻辑和插入消息表的消息组成了一个强一致性的事务,要么同时成功,要么同时失败。
- 完成 1)步的逻辑后,此时再向mq的ORDER_QUEUE队列中投递一条下单消息,这条下单消息的内容跟保存在订单库消息表的消息内容一致。
- mq接收到消息后,此时支付服务也监听到这条消息了,此时支付服务处理消费逻辑即开始生成支付凭证。
- 支付凭证生成后,再反向向mq投递一条消费成功的消息到ACC_QUEUE队列。
- 同时订单服务又来监听这个支付服务消费成功的消息,当订单服务监听到这个消费成功的消息后,此时再将本地消息表的消息状态改为“已发送”。
- 流程图中,任意一处崩溃都会导致分布式事务失败,此时并没有改变消息表中状态。因此,我们增加一个消息恢复系统(就是定时任务),来重复投递消息,确保消息能被正确消费。如果,在投递过程中失败,一般设置一个最大的重试次数,超过可以通过短信、钉钉、邮件的方式来进行一个人工的干预,经行一个人为保底
特点:
建设成本低,实现了可靠消息的传递确保了分布式事务的最终一致性
本地消息表与业务耦合在一起,难于做成通用性,不可独立伸缩;本地消息表是基于数据库来做的,而数据库是要读写磁盘IO的,因此在高并发下是有性能瓶颈的。
分布式事务消息
通过具有分布式事务消息的能力的消息队列(目前只有rocketmq支持官方文档),来确保分布式事务,具体流程如下:
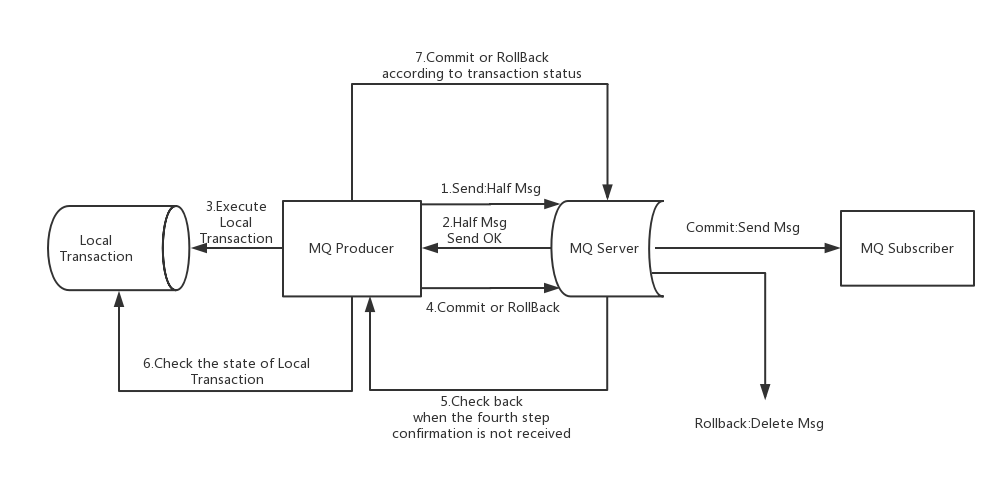
上图说明了事务消息的大致方案,其中分为两个流程:正常事务消息的发送及提交、事务消息的补偿流程。
- 事务消息发送及提交:
(1) 发送消息(half消息)。
(2) 服务端响应消息写入结果。
(3) 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)。
(4) 根据本地事务状态执行Commit或者Rollback(Commit操作生成消息索引,消息对消费者可见)
- 补偿流程:
(1) 对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次“回查”(默认15次,然后就rollback)
(2) Producer收到回查消息,检查回查消息对应的本地事务的状态
(3) 根据本地事务状态,重新Commit或者Rollback
其中,补偿阶段用于解决消息Commit或者Rollback发生超时或者失败的情况。
开发简单;可以支撑高并发业务
引入新的组件,系统复杂度增加;消息队列有丢失消息的风险
尽最大努力通知
这个方案的大致意思就是:
- 系统 A 本地事务执行完之后,发送个消息到 MQ;
- 这里会有个专门消费 MQ 的服务,这个服务会消费 MQ 并调用系统 B 的接口;
- 要是系统 B 执行成功就 ok 了;要是系统 B 执行失败了,那么最大努力通知服务就定时尝试重新调用系统 B, 反复 N 次,最后还是不行就放弃
开发简单。
适用于一些最终一致性时间敏感度低的业务,且被动方处理结果 不影响主动方的处理结果;不保证一致性。