InnoDB索引详解
环境:
操作系统:macos
数据库版本:mysql 8.0.23 innodb引擎
本文所有内容都是基于以上环境的,如果有异议的地方欢迎邮件交流。
什么是索引?
大家应该都有用过字典,我们查字典的时候有好几种方式。我这里拿拼音的方式举例,比如说我要查朱这个字,首先要找到z去字典拼音目录里面先找z,然后在找zhu这个拼音,最后通过后面的页码数找到朱的释义。这里,如果把字典比作数据库,那么拼音目录就是所谓的索引。
索引有什么用?
还是拿刚才查字典的动作举例,如果没有拼音目录,我们想找到朱字就只能一个个的去翻字典了,很慢。所以,明白没,索引作用就是加快查询的速度的。
自此,我们可以给索引下一个定义了:
索引是一种数据结构,可以用来加快查询速度
索引的物理结构
由于,我平时用mysql比较多,就以mysql数据库,innodb引擎来举例,聊下mysql的索引设计。根据官方文档,索引底层的数据结构是有B+树实现的,大概的结构如下图:
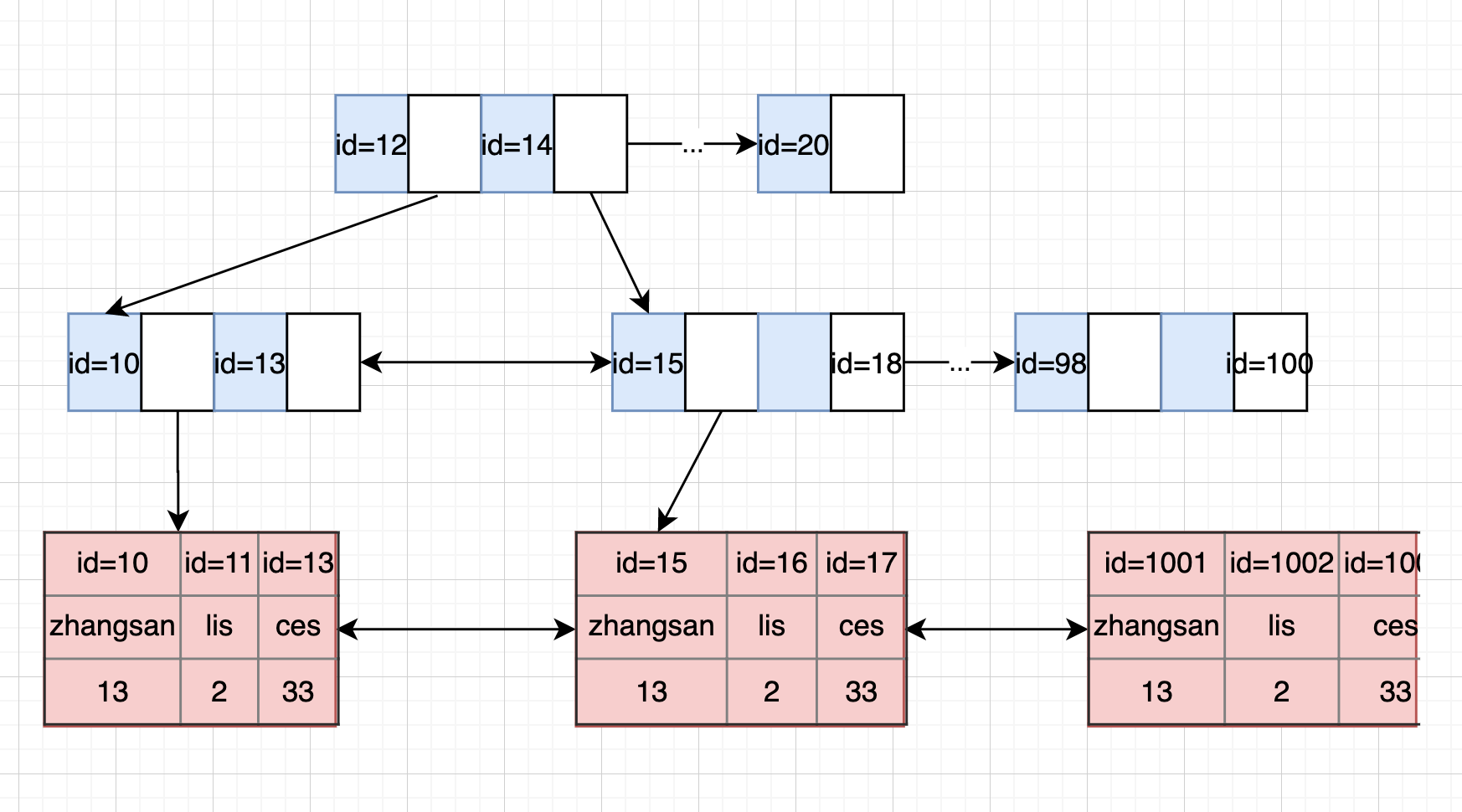
我们可以看到,实际存放数据的地方是最下面红色部分,红色部分中id与蓝色id重复,我们是先找到id,才能找到数据。那么id是什么?id代表聚簇索引(cluster index)。根据官方文档的说法,每次创建一张innodb引擎的表时,都会有一个特殊的索引,称之为聚簇索引,用于存储行数据。通常聚簇索引和主键等同,但是,如果你没有定义主键,那么就选第一个非空的唯一索引作为聚簇索引;如果还是没有的话,那么就会生成一个隐藏的聚簇索引叫GEN_CLUST_INDEX,这个id是一个6byte单调自增的数
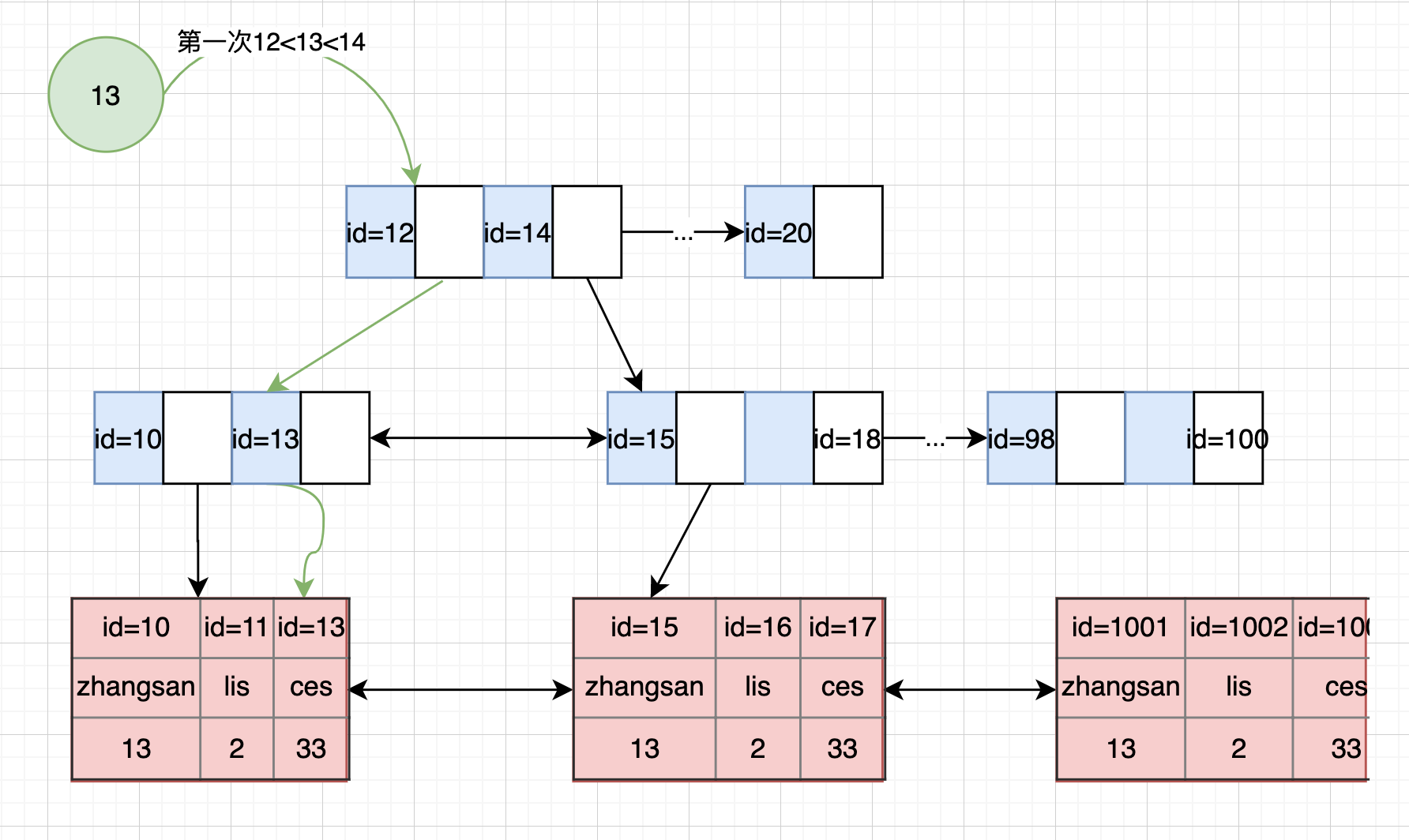
这里简述下数据库查询流程,假设我们有一条这样的sqlselect * from user where id=13,由于id=13,那么12<13<14那么就做左边的树下找到id=13的指向实际存储数据指针,再找到数据,就是这么一个简单的流程,具体如图:
实际使用中,我们不一定每次都用聚簇索引来查询,还会使用其他索引来辅助查询。这个时候,就会用到非聚簇索引,官方称之为二级索引。二级索引的查询流程构建在聚簇索引之上的,假设我们的sql是``select * from user where name=a`,具体执行流程如下:
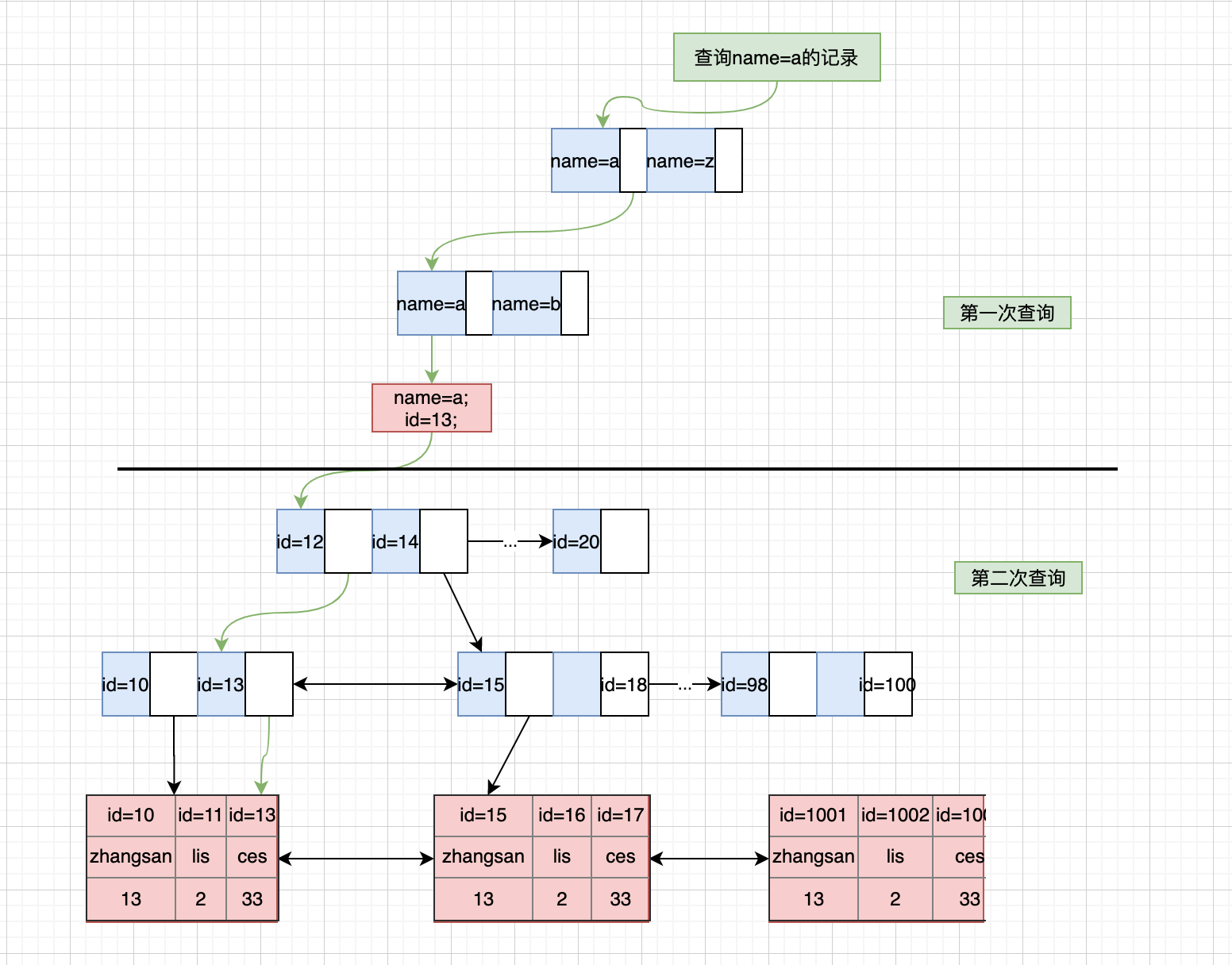
可以看出,二级索引第一次查询查的是表的聚簇索引,然后在通过聚簇索引反查用户的记录,这个过程被称作回表。如果,我查询结果只需要name和id两个字段的话,但是使用select *查询所有字段触发回表性能就很差。但是,如果使用select name, id只查需要的字段就在第一次查询时查到需要的字段,不会再进行第二次查询过程,提升了查询效率,这个叫索引覆盖。这就是为什么有的sql优化建议查询只需要查需要的字段,不止网络开销,还有这个方面的考量。
组合索引
组合索引我个人总是和聚簇索引搞混,但是其实是二级索引。他的结构和上面的差不多,只是是由多个字段组成,具体结构如下:
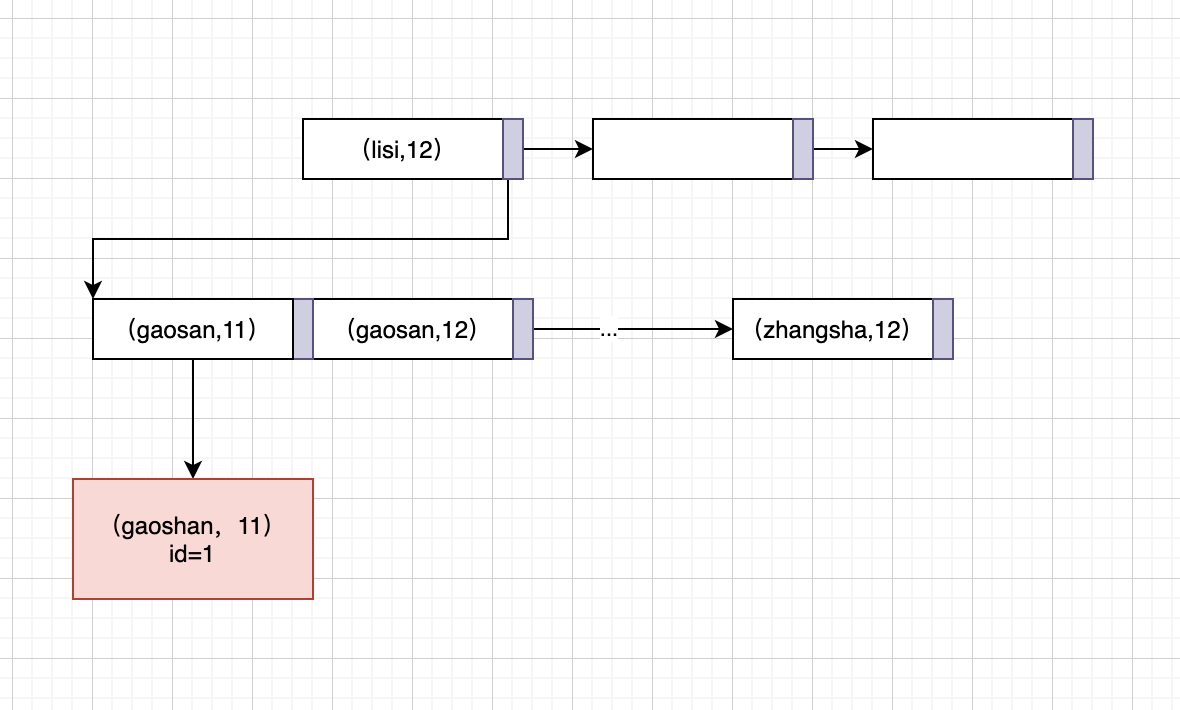
组合索引是先按照第一个索引字段查找,然后第一个字段相同按照第二个字段查找,这也就是为什么组合索引会有最左匹配原则这个东西。
一些索引的问题
NULL不走索引?
有很多博文说NULL不走索引,所以不能让字段为NULL。这个说法不准确,在我当前环境中,NULL是能够走索引的,结果如下:
explain select * from user where name is NULL;

可以看出NULL是走索引的,但是,还是不推荐使用NULL,因为会使索引、索引统计和值更加复杂,并且需要额外一个字节的存储空间。