redis高级部分
redis数据结构对应业务场景
sting业务场景
- 缓存结构体(对象)信息,一般是将其变成json字符串,然后保存
- 计数场景,一般用来实时计数统计、库存计数、限流计数等
list业务场景
- list当做消息队列使用
- list可用于秒杀抢购场景,防止超卖。在秒杀前将本场秒杀的商品放到list中,因为list的pop操作是原子性的,所以即使有多个用户同时请求,也是依次pop,list空了pop抛出异常就代表商品卖完了,例如:
//库存为3瓶可乐
> rpush goods:cola cola cola cola
(integer) 3
> lpop goods:cola
"cola"
> lpop goods:cola
"cola"
hash业务场景
保存结构体(对象)信息,不同于字符串一次序列化整个对象,hash可以对用户结构中的每个字段单独存储,比如购物车场景用hash就比string合适
set业务场景
set类似Java中hashset结构,内部的健值是无序唯一的,主要用在一些去重的场景,比如一个用户只能中奖一次等需要去重场景
zset业务场景
各类热门排序场景,例如热门歌曲榜单列表,value值是歌曲ID,score是播放次数,这样就可以对歌曲列表按播放次数进行排序;当然还有类似微博粉丝列表、评论列表等等,可以将value定义为用户ID、评论ID,score定义为关注时间、评论点赞次数等等。
hyperloglog业务场景
HyperLogLog可以使用在一些数据统计业务(不考虑单条数据,只统计独立总数),可以容忍一定的误差。Redis官方给出的误差率是0.81%。
比如:统计访问网站的IP,Uv数,在线用户数等
geo业务场景
主要用于地理位置相关,比如摇一摇,查找附近的人等功能
bitmap
Bit-Map 常用在数量大,且记录值与操作本身无关,与结果有关的事件。如:点赞,数目统计,活跃值,与结果有关,即可以用 0 或 1 代表结果统计的事件。就类似与古人打绳结来记录时间,也可以打绳结来记录点赞这一类事件。
redis线程模型
参考:redis线程模型
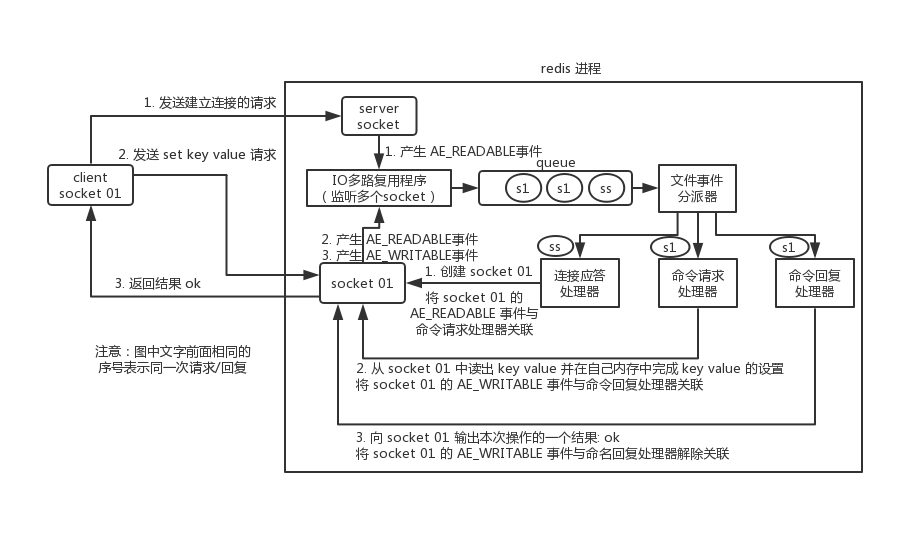
redis内部使用文件事件处理器file event handler,这个文件事件处理器是单线程的,所以redis才叫做单线程的模型。它采用IO多路复用机制同时监听多个socket,根据socket上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含4个部分:
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
来看客户端与 redis 的一次通信过程:
redis设置过期时间
Redis中有个设置时间过期的功能。作为一个缓存数据库,这是非常实用的。如我们一般项目中的token或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
如果我们设置了一批带了过期时间的key,那么当时间到了之后redis会如何处理这些key呢?
定期删除+惰性删除
- 定期删除:
Redis 默认会每秒进行 10 次(redis.conf 中通过 hz 配置)过期扫描,扫描并不是遍历过期字典中的所有键,而是采用了如下方法
- 从过期字典中随机取出 20 个键
- 删除这 20 个键中过期的键
- 如果过期键的比例超过 25% ,重复步骤 1 和 2
为了保证扫描不会出现循环过度,导致线程卡死现象,还增加了扫描时间的上限,默认是 25 毫秒(即默认在慢模式下,如果是快模式,扫描上限是 1 毫秒)
- 惰性删除:
在取出该键的时候对键进行过期检查,即只对当前处理的键做删除操作,不会在其他过期键上花费 CPU 时间
缺点:对内存不友好,如果一个键过期了,但会保存在内存中,如果这个键还不会被访问,那么久会造成内存浪费,甚至造成内存泄露
redis内存淘汰机制
如果redis中有许多过期key,定期删除漏掉很多,你也没有再次访问无法触发惰性删除,大量的key堆积在内存中,内存会很快耗尽,内存淘汰机制就是用来解决这个问题的。
redis提供8中内存淘汰机制:
- volatile-lru -> 从
已设置过期时间(server.db[i].expires)的数据集中挑选最近最少使用的数据淘汰 - volatile-ttl -> 从
已设置过期时间(server.db[i].expires)的数据集中挑选将要过期的数据淘汰 - volatile-random -> 从
已设置过期时间(server.db[i].expires)的数据集中挑选任意的数据淘汰 - volatile-lfu -> 从
已设置过期时间的数据集中挑选最不经常使用的数据淘汰 - allkeys-lru(最常用) -> 当内存不足写入新数据时淘汰
最近最少使用的Key - allkeys-lfu -> 当内存不足写入新数据时淘汰
最不经常使用的Key - allkeys-random -> 从数据集(server.db[i].dict)中任意选择数据淘汰
- noeviction(redis默认) -> 当内存不足写入新数据时,写入操作会报错,同时不删除数据
redis持久化机制
有时候我们需要备份数据,需要讲内存中的数据写入到硬盘,毕竟内存中的数据断电就消失了
redis支持两种持久化的方式,快照(snapshooting,特征是.rdb结尾的文件)和追加文件(特征是.aof结尾的文件)
快照(RDB)
redis默认采取快照的方式持久化数据,在redis.conf配置文件中,默认有一下配置:
#在900秒(15分钟)之后,如果至少1个key发生变化,redis自动触发bgsae命令创建快照
save 900 1
#在300秒(5分钟)之后,如果至少10个key发生变化,redis自动触发bgsae命令创建快照
save 300 10
#在60秒(1分钟)之后,如果至少10000个key发生变化,redis自动触发bgsae命令创建快照
save 60 10000
# 以上三个任一满足条件就会触发快照
追加文件(AOF)
与RDB方案比起来,AOF方案实时性更好。默认没有开启,开启需要在redis.conf配置文件通过appendonly yes开启
redis中存在3中不同AOF持久化方式:
# 每次有数据修改发生时都会写入aof文件,这个会严重降低redis速度
appendfsync always
#每秒钟同步一次,显示的将写命令同步到硬盘
appendfsync everysec #redis默认方案,也是我们常使用的方案
#让操作系统觉定
appendfsync no
redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
redis缓存雪崩、缓存穿透和缓存击穿
一般的缓存处理流程:
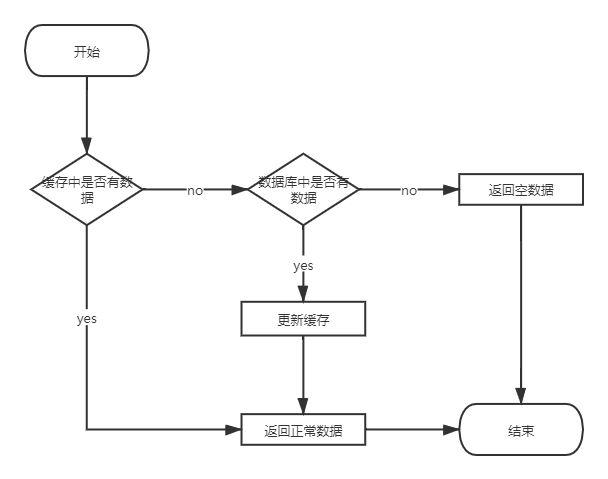
缓存穿透
描述:
指的是用户不断请求缓存数据库没有的数据,导致数据库压力过大
解决方案:
- 接口参数校验,拦截不符合规范的参数
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒
缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
- 设置热点数据不过期
- 加锁🔒(不推荐,性能很差)
缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机
解决方案:
- 设置缓存数据的过期时间随机,防止同时大量数据过期
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
- 设置缓存永不过期