mysql执行计划
前言
日常工作中,发现一些sql查询速度过慢,就会使用explain来查看执行计划,用以优化sql语句,用法如下:
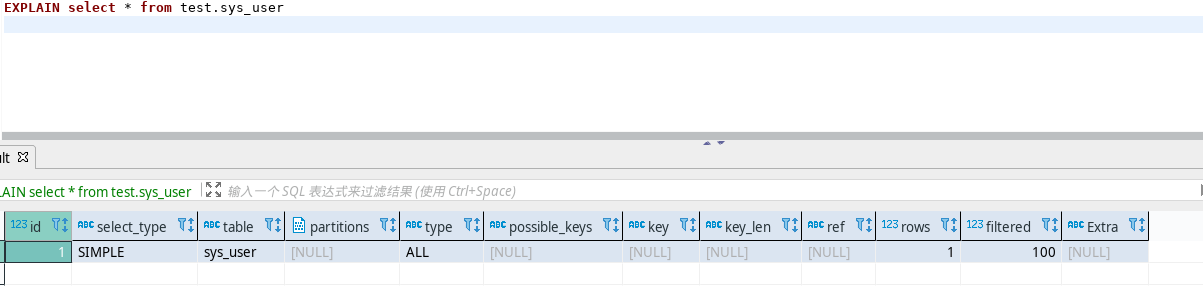
主要列详解
1.id
select 查询的序列号,表示查询中执行select子句或操作表的顺序
id有三种情况:
id相同,执行顺序由上到下
总结:加载顺序由上到下
- id不同,子查询的话id序号会递增
总结:执行顺序不同时,id值越大,优先级越高
上面两种情况同时存在
总结:id值相同认为是同一组,从上到下执行;在所有组中,id越大,优先级越高

2.select_type
表示select语句的类型
select_type Meaning SIMPLE 简单查询,不使用union或者子查询 PRIMARY 最外层的查询 UNION union语句中第二个以上的select语句 DEPENDENT UNION union语句中第二个以上的select语句,依赖子查询 UNION RESULT union查询的结果 SUBQUERY 子查询中的第一个select语句 DEPENDENT SUBQUERY 子查询中的第一个SELECT,依赖于外面的查询 DERIVED 导出表的SELECT(FROM子句的子查询) MATERIALIZED 物化子查询 UNCACHEABLE SUBQUERY 无法缓存结果的子查询,必须为外部查询的每一行重新计算 UNCACHEABLE UNION UNION 属于不可缓存的子查询的第二个或后一个选择
3.table
输出行的引用名称,可以是以下值:
<unionM,N>:指id为M和N的集合
<derived**N**>:用于与该行的派生表结果id的值 N。例如,派生表可以来自FROM子句中的子查询
<subquery**N**>:id 值为的行的具体化子查询的结果N
4.partitions
记录与查询匹配的分区,非分区表显示为NULL
5.type
type字段解释表示怎么连接的,以下列表描述从最好到最差的连接类型:
system
表只有一行数据(例如:系统表),这是const连接的特例const
表至多有一条匹配行,,const类型链接的表非常快,因为只读一次
example: SELECT * FROM tbl_name WHERE primary_key=1; SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2;eq_ref
eq_ref在连接操作时使用索引的所有部分并且索引是主键或者唯一键时被使用,只会从连接好的表记录中取一条记录
example: SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;ref
ref用户最左前缀或者键不是主键(换句话说,连接无法根据键值选择一行记录),会取出所有匹配到的记录
example: SELECT * FROM ref_table WHERE key_column=expr; SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;fulltext
使用FULLTEXT索引执行引擎
ref_or_null
类似ref,不过会额外搜索包含NULL值的行,这个通常用于子查询的优化
example: SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;index_merge
表示使用联合索引
unique_subquery
这个类型在以下IN 子查询中替换eq_ref,只是一个索引查找函数,来替换子查询获取更好的效果
example: value IN (SELECT primary_key FROM single_table WHERE some_expr)index_subquery
类似unique_subquery,只对以下形式的非唯一索引有效
example: value IN (SELECT key_column FROM single_table WHERE some_expr)range
使用索引选择行,只检索给定范围内的行。key列显示使用了哪个索引,一般就是在你的where语句中出现 =<>,>,>=,<,<=,is_null,<>,between,like or in() 等的查询
example: SELECT * FROM tbl_name WHERE key_column = 10; SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20; SELECT * FROM tbl_name WHERE key_column IN (10,20,30); SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30);index
FULL INDEX SCAN,index与all区别是index类型只遍历索引树,all全表
all
FULL TABLE SCAN全表遍历
possible_keys
表示查询时,能够使用的索引.不一定表示数据库查询的时候会真正用到,具体使用哪个索引由key字段决定
key
此字段是 MySQL 在当前查询时所真正使用到的索引.
key_len
表示查询优化器使用了索引的字节数. 这个字段可以评估组合索引是否完全被使用, 或只有最左部分字段被使用到
rows
MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数.
这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好.